Edward Lee Thorndike (1874-1949)

While Pavlov was developing a general model of learning
involving "reflexes" and
classical conditioning (an approach that was becoming popular
in Europe),
Thorndike was also carrying out experiments on animal learning.
Thorndike was
interested in how animals learn to solve problems. His approach
was fundamentally different than Pavlov's. While Pavlov was
interested in how animals react to various stimuli, Thorndike
was interested in how the animal responds to a situation in the
environment in an effort to achieve some result.
If Thorndike had been in Pavlov's lab he would have wondered
how dogs learn to
produce specific behaviour in order to get food. (For example,
some dog owners
insist that their dog sit before being given food. Thorndike
would have been
interested in how the animal learns this behaviour.)
Note that people had been interested in instrumental learning
for a number of years before Pavlov and Thorndike started their
experiments on learning. In particular, they were interested in
showing that animals were capable of
intelligent behaviour as a way of
defending Darwin's theory of evolution. This was considered
important because people who attacked the Theory of Natural
Selection argued that humans were fundamentally different than
other animals in terms of there ability to reason. What set
Thorndike apart from his predecessors was that he was the first
to investigate instrumental learning systematically using sound
experimental methods.
Thorndike's
Puzzle Box Procedure
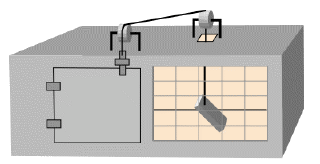
Thorndike placed a hungry cat inside a "puzzle box" with food
outside. Initially, the cat would become agitated and produce
many different "random" behaviours in an attempt to get out of
the cage. Eventually, the cat would press the paddle by chance,
the door would open and the cat could escape and get the food.
The cat would then be placed inside the box again and would
again take a long time (on average) to escape after exhibiting
many different behaviours.
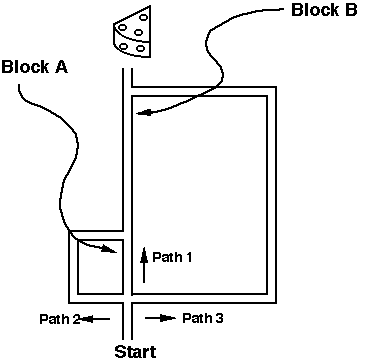
Puzzle Box
Thorndike examined the time to escape (his operational
definition of learning was thus latency) as a function of
trials. The learning curve was gradual and uneven (see
below).
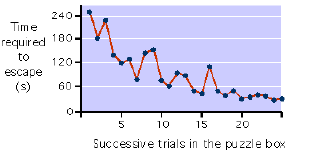
There was little evidence of sudden insight (intelligence in
the "Sherlock Holmes/CSI Miami" sense). Nevertheless, after
about thirty trials, the cats
would press the paddle almost as soon as they were placed in
the cage. Thorndike concluded that the animals learned by
"trial and success". Based on observation such as these,
Thorndike proposed a general theory of
learning which is called the
Law of Effect. This law of effect
states that:
"The consequences
of a response determine whether the tendency to
perform it is
strengthened or weakened. If the response is followed
by
a satisfying
event (e.g., access to food), it will be strengthened; of
the
response is not
followed by a satisfying event, it will be weakened."
The Law of Effect starts with the assumption that when an
animal encounters a
new environment, it will initially produce largely random
behaviours (e.g.,
scratching, digging, etc.). Over repeated trials, the animal
will gradually associate some of these behaviours with good
things (e.g., access to food) and these behaviours will be more
likely to occur again. In Thorndike's terms, these
behaviours are "stamped in". Other behaviours that have no
useful consequences are "stamped out" (see below).

Because, the more useful behaviours are more and more likely to
be performed,
the animal is more and more likely to complete the task
quickly. Thus, in the cat in the box example, the time to
escape will tend to decrease. Note that according to
Thorndike's view of learning, there is no need to postulate any
further intelligent processes in the animal. There is no need
to assume that the
animal notices the causal connection between the act and its
consequence and no need to believe that the animal was trying
to attain some goal. The animal simply learns to associate
certain behaviours with satisfaction such that these behaviours
become more likely to occur. Thorndike called this type of
learning
instrumental
learning. The animal learns to produce a response that
is intrumental in getting satisfaction.
Skinner and Operant
Learning
Burrhus Fredric Skinner (1904-1990)

Picking up on Thorndike's research on instrumental learning was
another Harvard graduate student in Psychology --approximately
40 years after Thorndike left Harvard for Columbia University
-- B. F. Skinner. Skinner replaced the term instrumental
learning with the term
operarant learning refined
Thorndike's terminology and methodology to fit the new
paradigm in psychology -- Behaviorism as well as Ernst Mach's
paradigmitic contribution to physics Operationalism. He began
by elucidating differences between Pavlovian/Watsonian type
classical conditioning and his operant learning--showing that
they were fundamentally different processes.
In classical
conditioning:
- a biologically significant event (US - meat) known to
elicit a hardwired reflex (UR) is associated with a neutral
stimulus (NS - bell),
- the neutral stimulus (NS) becomes a conditioned
stimulus (CS)an association strong enough to elicit, at
least partially, elements of that reflex --which is
now a learned or conditioned response (CR).
In operant
learning:
- a
biologically significant event is followed by a response,
not a stimulus,
- a
consequence of that response alters the strength of
association between a neutral stimulus context (e.g., the
operant chamber) and a quite arbitrary response (e.g.,
pressing the paddle). The response is not any part of a reflex and so Skinner termed it
a behavior rather
than a response to
distinguish it from Pavlovian Conditioning.
Skinner replaced Thorndike's term
instrumental responses with the
term
operant responses
or simply
operants
because they operate on the world to produce a consequence
(feedback from the world that has just been operated on). He
also referred to
instrumental
learning as
operant
learning. Thus, operant learning is: The process
through which the consequence of an operant (behavior) affects
the likelihood that the behavior will be produced again in the
future. Unlike reflexes, operant behaviors can be accomplished
in a number of ways (compare an eyeblink to pressing a paddle)
and are what we normally think of as voluntary actions. In
operant learning, the emphasis is on the consequences of a
motor act rather than the act in and of itself. Skinner, like
Thorndike, believed in the Law of Effect. He believed that
the
tendency to emit an operant behavior is strengthened or
weakened by the consequences of the response. However, he
avoided mentalistic terms and interpretations. Thus for example
he used the term
reinforcer,
instead of
reward, to refer to the
stimulus change that occurs after a behavior and tends to make
that behavior more likely to occur in the future. (The term
"satisfaction" was distasteful to Skinner due to its
anthropomorphizing and loose use of language . After all, how
can we know if a cat is satisfied by the food is gets when it
escapes from the cage? All we really know is that the behavior
leading to the food will be more likely to occur again in a
similar situation.) Thus Thorndike's law of effect becomes a
logical contingency:
If: B
x(A)
---> S
x(1) --->
B
x(A)=
 then:
then:
S
x(1)= S
R
If: B
x(A)
---> S
x(1) --->
B
x(A)=
 then:
then:
S
x(1)= S
P
and its first corrolary refers to the manner in which the
Punishing stimulus conditions (S
p) or the
Reinforcing stimulus conditions (S
r) are
achieved:
|
|
Bx(A)=
|
Bx(A)=
|
| Sx added
following Bx |
Positive
reinforcement
|
Positive
punishment
|
|
Sx removed
following Bx
|
Negative
reinforcement
|
Negative
punishment
|
Skinner Box
Skinner developed a new method for studying operant learning
using what is
commonly called a "Skinner box". Skinner boxes are also called
operant chambers.
Operant Chamber
Illustration

A Skinner box is a cage with a lever or some other mechanism
that the animal can operate to produce some effect, such as the
delivery of a small amount of juice. The advantage of the
Skinner box over Thorndike's puzzle box is that the animal does
not have to be replaced into the cage on each trial. With the
Skinner box, the animal is left in the box for the experimental
session and is free to respond whenever it wishes. The standard
measurement used by Skinner to assess operant learning was the
rate of responses. (This was Skinner's operational definition
of learning.) Skinner and his followers argued that virtually
everything we do can be understood as operant or instrumental
responses that occur because of their past reinforcement and
that this is independent of whether or not we are aware of the
consequences of our behaviour. For example, if the students in
a class all smiled when the Professor walks to the right side
of the room but put on blank expressions when he or she walks
to the left, there is a good chance that the Professor will end
up spending most of the lecture on the right - even thought he
or she is not aware of what is happening. A more simple effect
you can have on your Professor is to simply be alert and
enthusiastic. This will tend to make him or her more
enthusiastic and you will get a better lecture.
Four Consequences of
Behaviour
As mentioned above, Skinner believed that operant behaviour
(i.e., operant
responses) is determined by its consequences. He identified
four possible
consequences of behaviour:
1) Positive
Reinforcement
Any stimulus that
increases the probability of a behaviour (e.g.,
access to fish is a positive
reinforcer for a cat).
Familiar examples of positive
reinforcement: studying and gambling.
2) Negative
Reinforcement
Any stimulus whose removal
increases the probability of a behaviour.
For example, bar pressing that
turns off a shock.
3) Positive
Punishment
Any stimulus whose
presence (as opposed to absence in -ve
reinforcement) decreases the
probability of behaviour. For example,
bar press that leads to a
shock.
4) Negative
Punishment
Any stimulus whose removal decreases
the probability of a behaviour. Skinner thought that punishment
was the least effective of the 4 possible consequences for
learning.
Processes Associated with
Operant Conditioning
As with classical conditioning, there are a number of processes
in operant
conditioning.
Shaping
Imagine a rat in Skinner box where a pellet of food will be
delivered whenever the animal presses a lever. What happens if
the rat in a Skinner box never presses the lever? To deal with
this problem, one can use a procedure known as "shaping". One
might start by providing the reinforcement when the rat gets
close to the lever. This increases the chance that the rat will
touch the lever by accident. Then you provide reinforcement
when the animal touches the lever but not when the animal is
near the lever. Now you hope the animal will eventually press
the lever and, when it does, you only reinforce pressing.
Thus, shaping involves reinforcing behaviours that are
increasingly similar to
desired behavior. (Shaping is sometimes called the method of
successive
approximations.)
 Extinction and Spontaneous
Recovery
Extinction and Spontaneous
Recovery
Extinction in operant conditioning is similar to extinction in
classical conditioning. If the reinforcer is no longer paired
with the response, the response decreases. e.g., people stop
smiling if you do not smile back.
The response also exhibits spontaneous recovery some time after
the extinction session.
Extinction of operant learning
has two non-intuitive facts:
1. The larger the Reinforcer, the more rapid the
extinction.
2. The greater the number of training trials,
the more rapid the extinction.
This may reflect the fact that the onset of extinction is
more "obvious".
Stimulus Control
The instrumental or operant response in operant condition is
not elicited by an external stimuli but is, in Skinner's terms,
emitted from within. But this does not
mean that external stimuli have no effect. In fact they do
exert considerable control over behaviour because they serve as
discriminative stimuli.
Suppose a pigeon is trained to hop on a treadle to get some
grain. When a green
light comes on, hopping on the treadle will pay off, but when a
red light comes on it will not. In this case, the green light
becomes a positive discriminative stimuli (
S+) and the red light becomes a
negative discriminative stimuli (
S-).
Note that the
S+ does
not signal food in the way that the
CS+ might in a Pavlov's
laboratory. (Recall the example with the black and gray squares
where after
training the animal salivates in response to a black square,
the
CS+, but not a gray
square.) Instead, the
S+ signals a particular
relationship between the instrumental response and the
reinforcer telling the pigeon "if you jump now, you will get
food." A variety of techniques have been used to study the role
of discriminative stimuli in operant learning and many of the
results mirror those of generalization of discrimination in
classical conditioning.
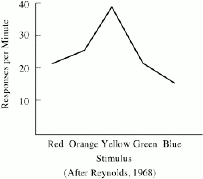
For example, if a pigeon is trained to respond only when a
yellow light appeared,
after training, it will also respond to lights of a different
colour. However, there is a response gradient - the response
decreases with the size of the difference
(measured in terms of wave frequency) between the test light
and original yellow
light (i.e., the original discriminative stimulus).
The following cartoon illustrates an experiment in which a rat
learns to discriminate between a triangle and a square in order
to get food.
Discriminative Stimuli (after Lashley,
1930)
 Reinforcement Schedules in
Operant Conditioning
Reinforcement Schedules in
Operant Conditioning
A major area of research in Operant Learning is on the effects
of different
reinforcement schedules. The first distinction is between
partial and continuous
reinforcement.
-
Continuous
Reinforcement: every response is reinforced
-
Partial or Intermittent
Reinforcement: only some responses are
reinforced.
In initial training, continuous reinforcement is the most
efficient but after a response is learned, the animal will
continue to perform with partial reinforcement. Extinction is
slower following partial reinforcement than following
continuous reinforcement. Skinner and others have described
four basic schedules of partial reinforcement which have
different effects on the rate and pattern of responding.
We have fixed and variable interval and ratio schedules.
Ratio schedules: reinforcer given
after some number of responses.
Interval schedules: reinforcer
given after some time period.
Fixed: the number of responses or
time period is held constant.
Variable: the number of responses
or the time period is varied around a mean.
Typical Behaviour with the 4
Schedules:
-
Fixed-Ratio: bursts
of responses.
-
Variable-Ratio:
extremely high, steady rate of responding. (Slot machines
work on a VR schedule). Known to produce extreme behavior
patterns categorized as compulsive or addictive behavior
patterns
-
Fixed-Interval:
pauses with accelerating responses as the time approaches
(the "scallop
effect").
-
Variable-Interval:
after training, a slow, steady pattern of responses is
usually seen.
Response rate is generally higher with the ratio
schedules.
Yes I know that Operant Learning Theory is:
laiden with terms, but we need this exact vocabulary to avoid
misunderstandings that might occur if we relied on layman's
terms.
Example: Although we commonly
understand that a "reward" provides a subject with some
psychological pleasure or satisfaction, the term has at least 3
significant drawbacks for the scientist:
1. It is difficult to quantify notions such as
"pleasure"
2. What is pleasurable to one person isn't necessarily to
another;
3. Perhaps most important, the concept of reward tells us
nothing about how behavior will be affected by the
stimulus.
Reinforcer, on the other hand, is more carefully
defined. Indeed, whether an event is a reinforcer depends
only on the effect it has on behavior.
Primary vs. Conditioned
Reinforcement:
The final part of the puzzle comes
in the form of conditioned reinforcement (S
r)
NOTICE THE
LOWER CASE "r"!!!. This is a concept that seems to cause
a fair amount of confusion, so follow along...imagine a rat in
an operant chamber who has learned that if it presses a lever
when a green light is on it will receive food (an example of a
Primary Reinforcer--stimuli needed for survival by the organism
--food, water, oxygen, etc.) But
not
when a red light is on. In the example of our friend the rat,
above, the
S+
component seems pretty straight-forward. But the green light,
because it has been associated with food in the past, can be
used as a reinforcer to maintain behavior as well. Like a
CS, the reinforcing
properties of the green light exist because of the unique past
history of this individual rat (rats which have not been
trained in the presence of green lights signaling the
availability of food show little interest in green lights).
Lever pressing can be maintained, at least to some extent, by
making the appearance of the green light contingent upon some
behavior of the rat, such as pressing another lever. Now,
where S
r gets complex (sorry!) is that there
are two basic types of conditioned reinforcement--one type
(
token reinforcement)
in which the S
r is a necessary step along the
way to receiving Primary reinforcement (S
R), and one
in which S
r is not a necessary condition for
obtaining reinforcement but has reinforcing properties because
it has been associated with powerful primary/biologically
significant reinforcing events in the past. Most discussions
of S
r are about token reinforcement. The term
refers to the fact that with this type of reinfrocement,
the S
r must be accumulated (like money, or
tokens) before the Primary reinforcement (S
R) can be
obtained. For example, getting points on a test, a grade in a
class, etc., are examples of token reinforcement in that a
student needs to pass a test (get points, or tokens), get a
passing grade in a class, etc., to eventually graduate and get
a diploma (another S
r, but more on this later).
In this case, S
r makes perfectly good sense
that it will maintain behavior, since the bigger contingency
out there can't be had without picking up this one along the
way. That's not to say that the S
r is
unimportant; it does maintain the behavior by providing a
small, but immediate, reinforcement for the behavior.
The other kind of S
r is usually much more
subtle. We don't need to get it, like we do with the "necessary
step" type. But it is still very important in our lives.
Getting a smile when we've said an encouraging word to a
friend, or receiving a smile when we really need it, may not be
necessary (in that it is not tied into a larger reinforcement
system), but it still "feels good". And why does a smile have
reinforcing properties? Because, like the green light for the
rat, it has been present when other "good" things have happened
to us.
Operant Learning (B.F. Skinner
in his own
words)